Loss function
Ở các phần trước, ta đã bỏ rất nhiều công sức để xây dựng được một công thức tổng quát để tìm ra một model từ một tập dữ liệu. Đó hàm mục tiêu của regularized loss minimization (RLM):
$$ w^* = \arg\min{w} \mathcal{L}{D_{train}}^{ERM}(w) + \lambda R(w)
$$
Nhưng suy đi nghĩ lại thì công thức này khá là "vô dụng" vì nó tổng quát nhưng không cụ thể. Ta chẳng thể dùng nó để luyện ra model nào bởi ta không biết $$\mathcal{L}$$ có dạng thế nào để mà tìm giá trị cực tiểu. Vậy tại sao chúng ta lại bỏ thời gian ra "vô ích" như vậy?
Tại sao chúng ta lại cần một công thức tổng quát?
Câu trả lời rất đơn giản, tiết kiệm năng lượng. Không riêng gì machine learning, trong mỗi ngành nghề đều tồn tại những công việc cần phải lặp đi lặp lại nhiều lần. Trong xây nhà thì đó là việc đổ móng, xây tường, lợp mái. Trong võ thuật thì đó là việc đứng tấn, đấm và đá. Những việc đó vô cùng nhàm chán và ta muốn dành thật ít năng lượng và suy nghĩ khi làm chúng! Ta thích làm những việc vui hơn, tự do hơn, sáng tạo hơn, như thiết kế hay trang trí một căn nhà, hoặc ngẫm ra một thế võ độc tôn.
Nhưng hãy tưởng tượng rằng nếu bức tường ta xây cứ ba ngày lại đổ một lần. Cứ xây đi xây lại như thế thì cả đời ta cũng không thể có cơ hội để trang trí một căn nhà. Tương tự, nếu chân đứng còn chưa vững thì nói gì đến việc sáng chế chiêu thức. Thế nên, muốn làm việc cao cấp vui vẻ thì trước hết phải làm những việc cơ bản nhàm chán thành thục trước đã.
Machine learning cũng như vậy. Ta bỏ nhiều công sức ra để xây dựng nên RLM là bởi nguyên tắc này được sử dụng trong hầu hết mọi model. Nếu bạn nắm kỹ RLM, thì tốc độ học của bạn sẽ được đẩy lên rất nhiều. Vì sao? Hãy nhìn vào công thức RLM, mảnh ghép còn thiếu cuối cùng chỉ là dạng của loss function $$L$$. Cho nên, mỗi lần bạn đọc tài liệu và gặp một dạng model mới, nếu nhận ra được bóng dáng của RLM trong đó thì gần như là "job done!". Công việc của bạn lúc đó chỉ là nhìn ra dạng của loss function với từng model khác nhau. Công việc sáng tạo model mới cũng được thi hành một cách bài bản hơn. Bạn đã có RLM làm nền, công việc của bạn chỉ là ngồi sáng tạo ra các biến thể của loss function để lắp vào.
Bây giờ ta sẽ đi nghiên cứu một số biến thể thông dụng nhất của loss function nhé!
Định nghĩa loss function
Loss function kí hiệu là $$L$$, là thành phần cốt lõi của evaluation function và objective function. Cụ thể, trong công thức thường gặp:
$$ \mathcal{L}D(f_w) = \frac{1}{|D|} \sum{(x, y) \in D} L \left( f_w(x), y \right)
$$
thì hàm $$L$$ chính là loss function.
Loss function trả về một số thực không âm thể hiện sự chênh lệch giữa hai đại lượng: $$\hat{y}$$, label được dự đoán và $$y$$, label đúng. Loss function giống như một hình thức để bắt model đóng phạt mỗi lần nó dự đoán sai, và số mức phạt tỉ lệ thuận với độ trầm trọng của sai sót. Trong mọi bài toán supervised learning, mục tiêu của ta luôn bao gồm giảm thiểu tổng mức phạt phải đóng. Trong trường hợp lý tưởng $$\hat{y} = y$$, loss function sẽ trả về giá trị cực tiểu bằng 0.
Hai dạng bài supervised learning cơ bản
Ta phân chia các dạng bài supervised learning dựa vào tính chất của $$y$$. Để đơn giản, ta xét bài các bài toán mà $$y$$ có thể biểu diễn được bằng một con số.
Khi $$y$$ là một số thực dao động trong khoảng $$(-\infty,\infty)$$, ta được một bài toán regression. Ví dụ như ta cần tiên đoán giá cổ phiếu, giá xăng, giá vàng vào ngày mai.
Khi $$y$$ là một đại lượng rời rạc chỉ nhận giá trị trong một tập label hữu hạn rời rạc nào đó, ta được bài toán classification. Ví dụ, khi ta cần nhận dạng tên một người từ một tấm ảnh chân dung, cho dù có hàng tỉ cái tên trên thế giới thì tập hợp này vẫn là rời rạc hữu hạn. Vì thế, bài toán này vẫn được quy vào dạng classification. Để đơn giản các công thức, bài viết này chỉ đề cập đến binary classification, tức là khi tập các label chỉ có hai phần tử ("có" hoặc "không", "đúng" hoặc "sai", "positive" hoặc "negative", ...). Để tiện cho việc tính toán, trong binary classification, ta chuyển đổi tập label thành tập $${-1, +1}$$ (-1 nghĩa là "không", +1 nghĩa là "có").
Lưu ý rằng ta đang nói đến label thật $$y$$ chứ không phải label dự đoán $$\hat{y} = f_w(x)$$. Thông thường, đối với cả regression và binary classification, ta đều thiết kế để model $$f_w(x)$$ trả về một số thực $$\hat{y} \in (-\infty,\infty) $$. Với regression, $$\hat{y}$$ dĩ nhiên mang ý nghĩa là giá trị được dự đoán. Với binary classification, $$\hat{y}$$ là điểm số thể hiện model ưa thích label nào hơn trong hai label. Nếu $$\hat{y} < 0$$ tức là model thích phương án -1 hơn và ngược lại, nếu $$\hat{y} \geq 0$$ tức là model nghiêng về phương án +1 hơn. Giá trị tuyệt đối của $$\hat{y}$$ thể hiện mức độ thích của model đối với lựa chọn của mình.
Cách xây dựng loss function
Vì loss function đo đạc chênh lệch giữa $$y$$ và $$\hat{y}$$, nên không lạ gì nếu ta nghĩ ngay đến việc lấy hiệu giữa chúng:
$$ L(\hat{y}, y) = \hat{y} \ - \ y
$$
Tuy nhiên hàm này lại không thỏa mãn tính chất không âm của một loss function. Ta có thể sửa nó lại một chút để thỏa mãn tính chất này. Ví dụ như lấy giá trị tuyệt đối của hiệu:
$$ L(\hat{y}, y) = |\hat{y} - y|
$$
Loss function này không âm nhưng lại không thuận tiện trong việc cực tiểu hóa, bởi vì đạo hàm của nó không liên tục (nhớ là đạo hàm của $$f(x) = |x|$$ bị đứt quãng tại $$x = 0$$) và thường các phương pháp cực tiểu hóa hàm số thông dụng đòi hỏi phải tính được đạo hàm. Một cách khác đó là lấy bình phương của hiệu:
$$ L(\hat{y}, y) = \frac{1}{2}(\hat{y} - y)^2
$$
Khi tính đạo hàm theo $$\hat{y}$$, ta được $$\nabla L = \frac{1}{2} \times 2 \times (\hat{y} - y) =\hat{y} - y$$. Các bạn có thể thấy rằng hằng số $$\frac{1}{2}$$ được thêm vào chỉ để cho công thức đạo hàm được đẹp hơn, không có hằng số phụ. Loss function này được gọi là square loss. Square loss có thể được sử dụng cho cả regression và classification, nhưng thực tế thì nó thường được dùng cho regression hơn.
Đối với binary classification, ta có một cách tiếp cận khác để xây dựng loss function. Nhắc lại là đối với dạng bài này, thì nếu model trả về $$\hat{y} < 0$$ tức là thích đáp án -1 hơn, trả về $$\hat{y} \geq 0$$ tức là thích đáp án +1 hơn.
Một cách rất tự nhiên, ta thấy rằng loss function của binary classification cần phải đạt được một số tiêu chí sau:
Ta cần phải phạt model nhiều hơn khi dự đoán sai hơn là khi dự đoán đúng. Vì thế, tiêu chí đầu tiên của ta là khi model dự đoán sai ($$y$$ khác dấu với $$\hat{y}$$), loss function phải trả về giá trị lớn hơn so với khi model dự đoán đúng ($$y$$ cùng dấu với $$\hat{y}$$).
Nếu có hai đáp án $$\hat{y}_1$$ và $$\hat{y}_2$$ đều cùng dấu (hoặc khác dấu) với $$y$$ thì ta nên phạt đáp án nào nhiều hơn? Như đã nói, giá trị tuyệt đối $$|\hat{y}|$$ thể hiện "độ thích" của model đối với một phương án. Giá trị này càng lớn thì model càng "thích" một phương án. Trong trường hợp $$\hat{y}$$ cùng dấu với $$y$$, phương án được thích là phương án đúng, do đó, model càng thích thì ta phải càng khuyến khích và phạt ít đi. Cũng với lập luận như vậy, nếu $$\hat{y}$$ khác dấu với $$y$$, vì phương án được thích là phương án sai nên model càng thích thì ta phải càng phạt nặng để model không tái phạm nữa.
Một cách tổng quát, đối với binary classification thì các loss function thường có dạng như sau:
$$ L(\hat{y}, y) = f(y \cdot \hat{y})
$$
trong đó $$f$$ là một hàm không âm và không tăng.
Câu hỏi 1: Giải thích tại sao hàm $$g(\hat{y}, y) = \ - y \cdot \hat{y}$$ lại thỏa mãn hai tiêu chí đã nêu ở trên.
Câu hỏi 2: Giải thích tại sao hàm $$g(\hat{y}, y) = \ - y \cdot \hat{y}$$ lại không thỏa điều kiện của một loss function (lưu ý tính chất của loss function và $$f$$).
Các loss function cơ bản dành cho binary classification
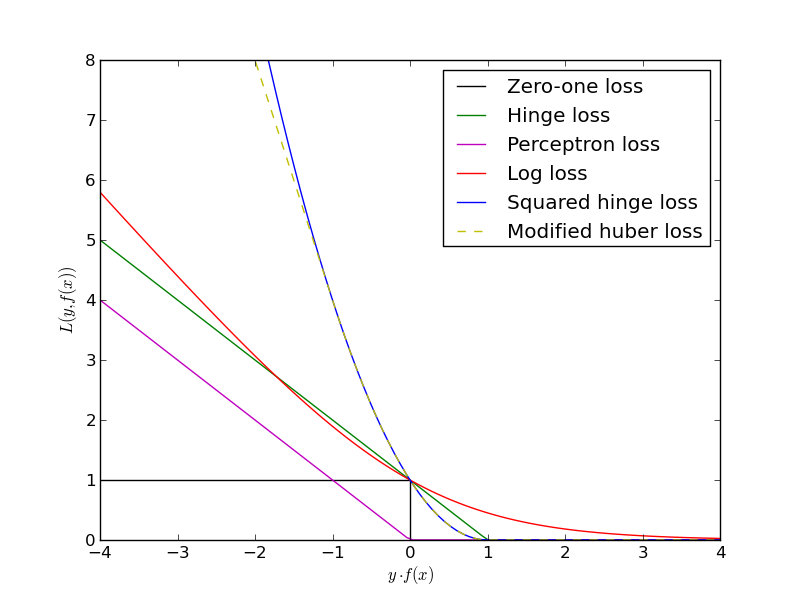
0-1 loss
Hàm này rất đơn giản: trả về 1 nếu $$y \cdot \hat{y} < 0$$, trả về 0 nếu ngược lại. Việc này tương đương với việc đếm số câu trả lời sai của model. 0-1 loss thường chỉ được dùng để tính error rate của model, chứ không dùng để huấn luyện model vì đạo hàm của nó không xác định ở điểm 0.
Perceptron loss
$$ L_{perceptron}(\hat{y}, y) = \max(0,- y \cdot \hat{y})
$$
Ta thấy rằng hàm perceptron loss là một cách đơn giản nhất để sửa sao cho hàm $$g$$ ở câu hỏi trong phần trước trở thành không âm (thỏa điều kiện của một hàm mát). Đối với perceptron loss, khi model đoán đúng ($$\hat{y}$$ cùng dấu với $$y$$), $$- y \cdot \hat{y}$$ sẽ mang dấu âm. Tức là, khi đó $$L_{perceptron}(\hat{y}, y) = \max(0, negative) = 0$$. Nói cách khác, perceptron loss không phân biệt gì giữa các dự đoán đúng. Chúng đều không bị phạt. Đối với các dự đoán sai, thì perceptron vẫn tuân thủ theo nguyên tắc là model càng thích thì phạt càng nặng. Perceptron loss là loss function của perceptron model.
Hinge loss
$$ L_{hinge}(\hat{y}, y) = \max(0, 1 - y \cdot \hat{y})
$$
Hinge loss thực ra chỉ là một biến thể từ perceptron loss. Ta chỉ thêm 1 đơn vị vào đại lượng $$- y \cdot \hat{y}$$. Số 1 này có một ý nghĩa rất đặt biệt, được gọi là margin (lề). Các bạn sẽ thấy là hinge loss hoạt động gần như tương tự như perceptron loss chỉ trừ các dự đoán mà $$y \cdot \hat{y}$$ nằm trong khoảng $$[0, 1]$$. Chú ý là các dự đoán mà $$y \cdot \hat{y}$$ rơi vào khoảng này thì đều đúng. Hinge loss phân biệt các dự đoán đúng này theo nguyên tắc là model càng thích thì càng phạt nhẹ. Còn khi $$y \cdot \hat{y}$$ vượt quá 1 thì hinge loss lại không phân biệt nữa.
Vì sao lại làm như vậy? Những dự đoán ở trong margin $$[0, 1]$$ là những dự đoán gần ranh giới, là những lúc mà model lưỡng lự. Ý tưởng của hinge loss là muốn model phải thật rõ ràng và tự tin với những quyết định của mình. Do khi vẫn còn trong margin thì model vẫn bị phạt, nên model sẽ được khuyến khích để đưa ra những quyết định đúng và có tính chắc chắn cao, nằm ngoài margin để không bị phạt nữa. Đây chính là ý tưởng của support vector machines model.
Logistic loss (hay log loss)
$$ L_{log}(\hat{y}, y) = \log_2(1 + \exp(- y \cdot \hat{y}))
$$
Trong công thức trên, hàm $$\exp(\cdot)$$ là hàm lũy thừa theo cơ số tự nhiên $$e$$. Thoạt nhìn log loss trông có vẻ khá phức tạp, và trông không có vẻ gì là họ hàng của hai hàm còn lại. Tuy nhiên, khi nhìn vào đồ thị của hàm số này, ta lại thấy rất dễ hiểu bởi vì nó thỏa tất cả mọi tính chất của loss function mà ta đã nói ở phần trước. Đây là một hàm liên tục, không âm và không tăng. Không những không tăng, log loss còn luôn giảm, có nghĩa là nó luôn phân biệt giữa các dự đoán có độ thích khác nhau bất kể đúng hay sai. Đây là điểm khác biệt chính của log loss với perceptron loss và hinge loss. Một điểm khác biệt nữa là hàm này có một độ cong nhất định, tức là nó không giảm với tốc độ như nhau ở mọi điểm. Trong khi đó, thì một phần của perceptron loss hoặc hinge loss chỉ là một đường tuyến tính, với tốc độ giảm là một hằng số. Log loss chính là nền tảng của logistic regression model.
Vậy có phải log loss là một loss function hoàn hảo? Chưa hẳn, điều này phụ thuộc vào bài toán. Tuy log loss đưa ra nhiều tiêu chí hấp dẫn, nhưng vấn đề model liệu có thể thỏa mãn những tiêu chí được những tiêu chí đó không. Hay chúng ta đang đòi quá nhiều ở model? Việc model phân biệt giữa một đáp đúng với độ chắn chắn thấp và một đáp án đúng với độ chắc chắn cao mang lại lợi ích gì cho ta? Có đôi khi, ta không quan tâm, đáp án nào cũng đều đúng. Có đôi khi, ta lại cần model phải rạch ròi. Có đôi khi, ta chỉ muốn tránh những đáp án có độ chắc chắn thấp; Lúc đó, hinge loss lại là sự lựa chọn tốt hơn. Tất cả đều tùy vào dữ liệu và ứng dụng.