Tinh chỉnh các hyperparameter
Khi bình thường hoá tham số xuất hiện trong hàm mục tiêu, vấn đề đặt ra là ta không nhất thiết phải đặt giá trị của hằng số bình thường hoá $$\lambda$$ giống nhau cho mọi bài toán. Hơn nữa, ngoài $$\lambda$$, còn có nhiều hyperparameter khác ta cần phải lựa chọn (như bậc của đa thức). Làm sao để chọn được tập giá trị tối ưu cho các hyperparameter với từng bài toán?
Development set
Để tinh chỉnh các hyperparameter, ta có thể là như sau: chọn một tập giá trị của các hyperparameter, huấn luyện để tìm ra một model rồi đo độ tốt của nó trên test set. Ta tiếp tục lặp lại quá trình này với nhiều tập giá trị hyperparameter khác nhau. Sau nhiều lần thử chọn như vậy, ta chọn tập giá trị nào cho độ sai sót thấp nhất trên test set.
Cẩn thận! Khi dùng test set để xác định hyperparameter, ta đã vi phạm nguyên tắc train-test độc lập. Nói một cách đơn giản là ta đã sử dụng test set để huấn luyện model làm model "đã thấy trước" được những gì mình sắp phải dự đoán. Để khắc phục điều này, ta cần đến một "test set thứ hai", chỉ chuyên dùng để tinh chỉnh các hyperparameter và không dùng để đưa thông báo cuối cùng về độ tốt của model. Ta gọi đấy là development set (tập phát triển). Development set cũng còn được gọi là validation set.
Trong bài viết trước, vì chưa nhắc giới thiệu khái niệm development set nên định nghĩa early stopping của mình cũng đã vi phạm quy tắc train-test độc lập. Cụ thể, vì thời điểm dừng huấn luyện phụ thuộc vào độ sai sót trên test set, mà model cuối cùng nhận được lại phụ thuộc vào thời điểm dừng huấn luyện, suy ra test set đã gián tiếp chỉ định model cuối cùng. Sau khi biết đến development set, để áp dụng early stopping một cách đúng đắn, thì ta chỉ việc thay learning curve trên test set bằng learning curve trên development set.
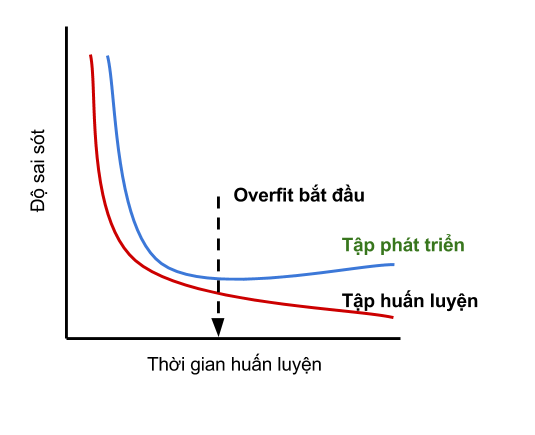
Trong nghiên cứu, tỉ lệ train:dev:test thường được dùng đó là 8:1:1. Tức là nếu có 100 điểm dữ liệu, thì lấy 80 điểm để huấn luyện, 10 điểm để phát triển, và 10 điểm để kiểm tra.
k-fold cross-validation
k-fold cross validation được sử dụng khi ta không có đủ dữ liệu để trích ra được một development set đủ lớn. Phương pháp này sẽ chia training set thành k phần. Sau đó, ta lần lượt sử dụng một phần làm development và k - 1 phần còn lại làm training set. Độ tốt của model (lúc phát triển) sẽ bằng trung bình cộng độ tốt trên development set qua k lần huấn luyện đó.